France
Breadcrumb navigation
Hybrid MPI
Technical ArticlesNov 1, 2020
Ryota ISHIHARA (MPI Engineer), Kenji KANEMURA (MPI Manager)
AI Platform Division, NEC Corporation
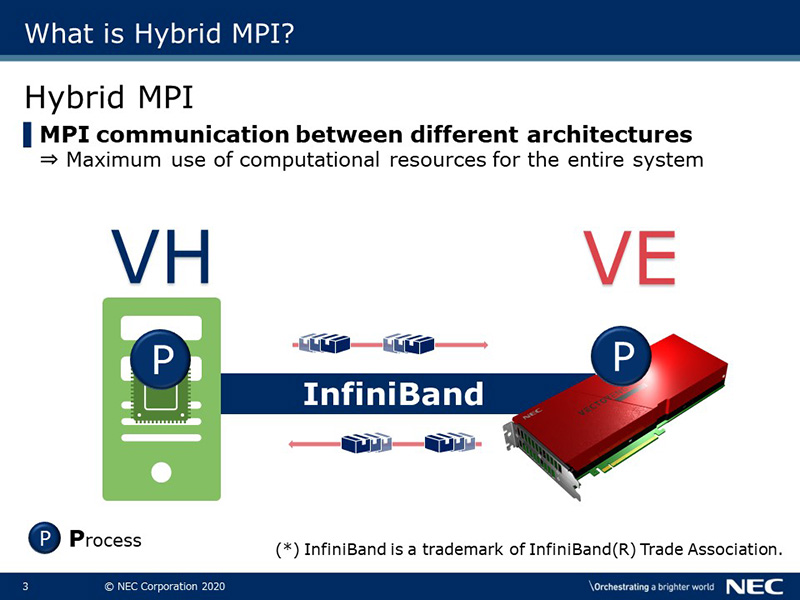
The NEC MPI available in Aurora systems can perform MPI communication not only within or between VEs, but also between different architectures. We call this feature Hybrid MPI. By using Hybrid MPI, both VH and VE computational resources can be used, which improves application performance. Please note that InfiniBand, which is high-speed interconnect, is required to use Hybrid MPI.

Hybrid MPI can perform MPI communication not only within a node but also between nodes. Of course, communication between VHs is also supported. By using Hybrid MPI, computational resources on VH can be used for MPI communication as well as VE, so the performance of the entire system can be maximized.
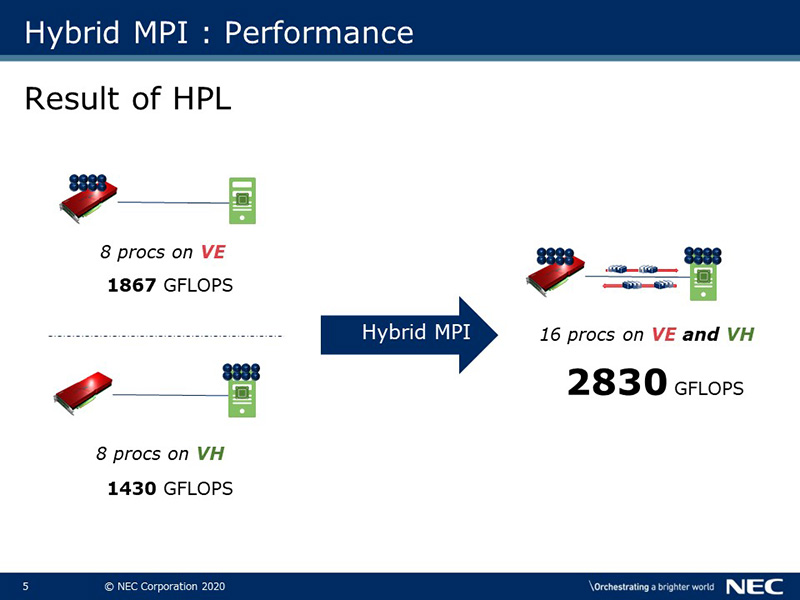
The above figure shows the results of HPL, which is a well-known HPC benchmark, for a single VE connected to a single VH.
The performance of 8 processes on the VE is 1867 GFLOPS, and the performance of 8 processes on the VH is 1430 GFLOPS. Using Hybrid MPI, 16 processes can be executed as a whole and the performance is 2830 GFLOPS. It is possible to get higher system performance by using both VE and VH.
Hybrid MPI can also be used to improve the efficiency of I/O processing. By creating a process for I/O processing on VH, it performs all transfer processing to a file server after transferring data from VE to VH by MPI communication.
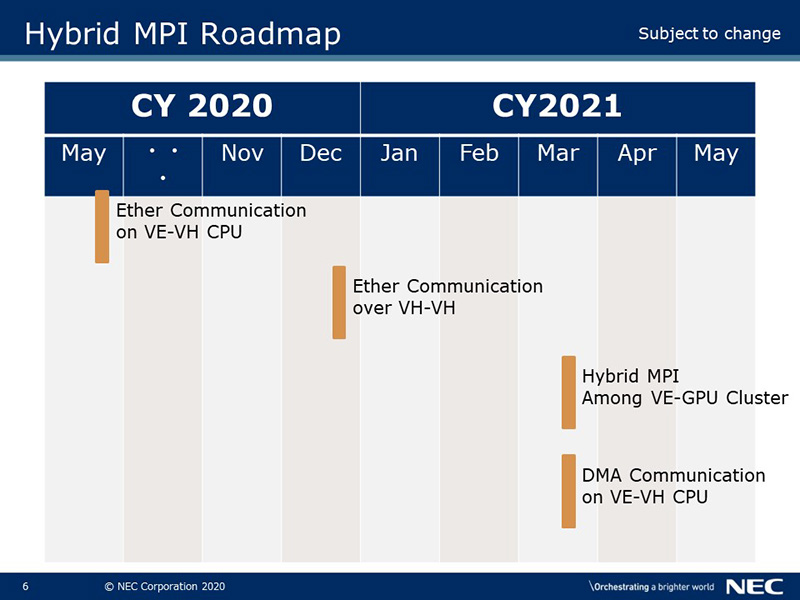
The first Hybrid MPI was released in October 2019. We plan to continuously enhance the features to make it easier to use and higher performance. At present, we are planning to enhance it about Ethernet and GPGPU.

In the previous Hybrid MPI, InfiniBand environment was indispensable even within one node, but we have enhanced it so that users who do not have InfiniBand environment can also use the Hybrid MPI.
Specifically, it is a library implementation that utilizes Ether communication via VEOS for various MPI communications that are normally expected to have high performance of OS bypass.
Therefore, compared to Hybrid MPI using InfiniBand environment, both latency and bandwidth are significantly inferior. However, even small customers who do not have InfiniBand environment can use Hybrid MPI, and they can select appropriate calculation resources, which are VH and VE, according to the application.
At the end of December 2020, Hybrid MPI communication using Ethernet between nodes will be available.
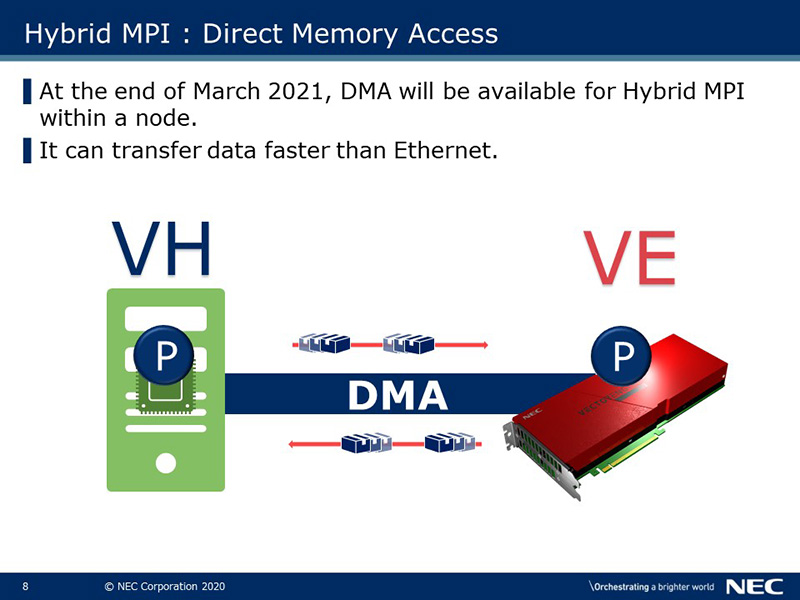
DMA will be available for hybrid communication within a node at the end of March 2021. It transfers data faster than Ethernet. Even without InfiniBand, the overhead of cooperation between VH and VE can be reduced compared to when using Ether, so it is expected that application performance will be further improved.
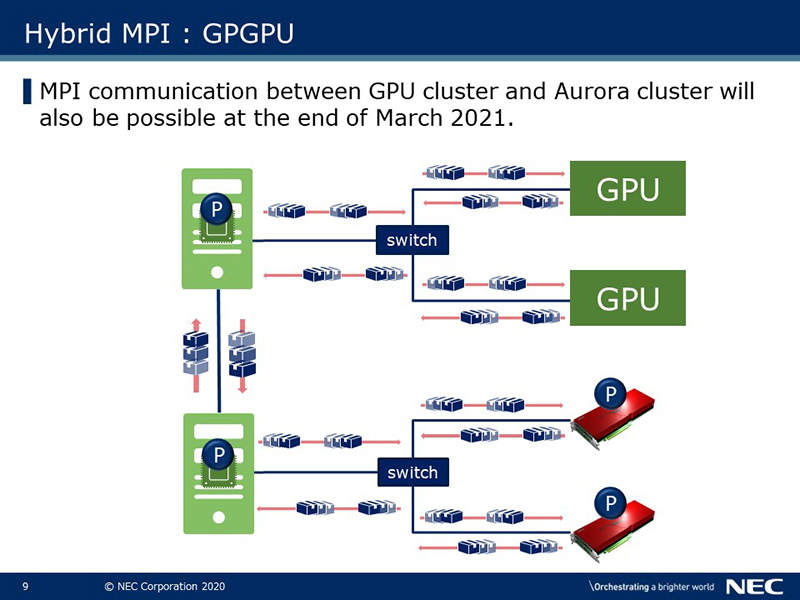
MPI communication between GPU cluster and Aurora cluster will also be possible at the end of March 2021. Application performance is maximized by allocating appropriate resources (VH [CPU], VE and GPU) according to the processing.
Previously, MPI communication was possible only between VEs. By using Hybrid MPI, however, the entire computational resources can be utilized even in a system where different architectures are mixed. So the performance of the application can be maximized. We believe Hybrid MPI will bring out your application performance.
- Intel and Xeon are trademarks of Intel Corporation in the U.S. and/or other countries.
- NVIDIA and Tesla are trademarks and/or registered trademarks of NVIDIA Corporation in the U.S. and other countries.
- Linux is a trademark or a registered trademark of Linus Torvalds in the U.S. and other countries.
- Proper nouns such as product names are registered trademarks or trademarks of individual manufacturers.